I was a little busy last week and I ended up not blogging about which project’s issues I was planning to tackle for our 0.4 release, oops. So, this week I’m going to roll the first and second blogs into one. I decided to work on telescope as I already had the environment setup on my system and had some familiarity with the backend. I looked through the issues with the backend label and found an issue regarding the removal of whitespace only blocks found in some posts. I decided I would take this issue as it was a step up from the blank post fix I made in release 0.3 and I figured that it was another issue I can fix with the power of regex.
I really like regex for some reason, working with it is sort of like solving a puzzle when trying to find the right combination of characters to find the matches you want in a piece of text. In this case our issue lies with empty <p> tags and repetitive <br> tags. Before I started creating the regex to solve the issue I decided to look through a number of posts to view the cases I might deal with.
When looking for empty <p> tags I considered any type of whitespace (spaces, tabs and newlines) with no text and tags that immediately close with </p> to be empty. I noticed some posts had <br> tags inside <p> tags with nothing else as well so I added that to the list of cases which should cover the different types of empty we can expect from RSS feeds. The other case was the usage of <br> tags back to back which is more straightforward than finding empty <p> tags.
Now, equipped with the knowledge of the potential cases I can run into I created the regex to find empty <p> tags and back to back <br> tags. The first regex I created was for finding repetitive <br> tags which looks like this: (<br>(\s?)+?){2,}. I wrote a little snippet of text which can be used to test the regex and plugged into regex101. The regex ended up highlighting all repetitive <br> tags like so:
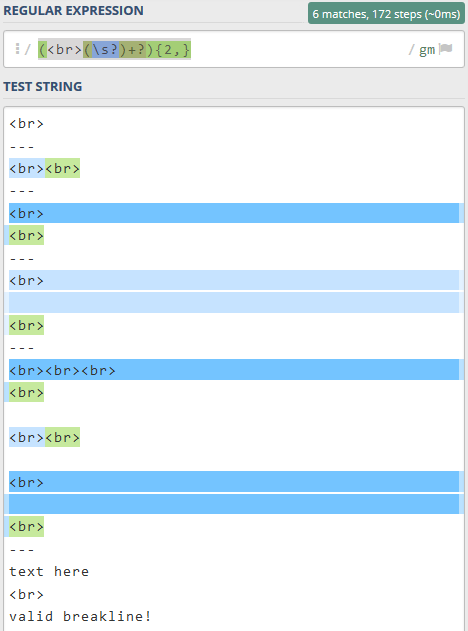
Basically the regex looks for any <br> text and then 1 or more instances of whitespace only if it exists with the {2,} telling it to look for 2 or more instances.
With that issue solved I moved onto creating the regex for finding empty <p> tags. I decided to create the <br> regex first as I could re-use it for the regex we’re about to create as <br> tags in a <p> tag and nothing else are also empty as I mentioned previously. This regex is a bit more nasty: <p>(\s+)?((<br>(\s?)+?){1,})?(\s+)?<\/p>. Again, I wrote a little snippet for testing and these were the results:
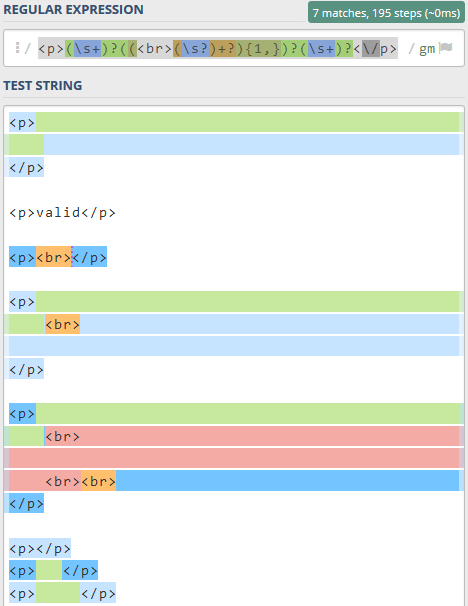
This regex looks for any text that starts with <p> and ends with </p> and looking for any instances of whitespace of any length and/or <br> tags using the same regex from above except looking for 1 or more instances.
All I need to do now is add this to post-processing part of the backend by replacing repetitive <br> tags with a single one using the first regex, and completely erasing empty <p> tags with the second regex. Of course the text snippets I created will be used to create tests for the two functions I plan on implementing for the removal of these whitespace elements.
Thanks for reading!
